
ABSTRACT
Sept. 21 (Sat.)
|
[SESSION 3] 'Spaces Beyond the Human: An Expanded Analysis of Traversable Space in Video Games' Juan F. Belmonte (University of Murcia, Spain, Department of English Studies. Research Associate and Ph.D. Candidate) This paper studies virtual spaces in video games that resist traditional ideological analyses and proposes a theoretical framework for their study. First, it briefly reviews existing research on space in games (Frasca 2003, Jenkins 2004, Juul 2002, Nitsche 2008) in order to show that most available research focuses on the navigation of very specific types of space by humanoid avatars with easily recognizable gender and racial marks. The popularity in studies of urban space of the cities of the Grand Theft Auto series and their protagonists is a prime example of this. [Key Words: Virtual Space, Video Games, Identity, Ideology, Avatar]
References 'The Hub and Spoke Model of Digital Humanities Infrastructure' Jennifer Edmond (Director of Strategic Projects in the Faculty of Arts Humanities and Social Sciences at Trinity College Dublin) The most common image deployed in discussions of cyber-infrastructure is that of the road: concrete (literally!), linear, public and established. But the applications of this metaphor usually act as a shorthand for a desired essence of availability and accessibility, ignoring both the lessons the original image can teach us and the actual properties of a modern digital research infrastructure, which are so different from those of road transport. In particular, the European Digital Research Infrastructure for the Arts and Humanities (DARIAH) and its constituent national partners and formational projects, can be far more easily described - and productively understood - through the application of a hub-and-spoke model, such as is the basis for many modern airport/airline relationships. Within this new metaphor come a number of intriguing insights and issues for digital infrastructure, including the ideas of directionality, dimensioning, up- or downgauging, ancillary services and hub bypass. Directionality in the airline context refers to the efficiency of connections between incoming traffic and ongoing connecting traffic. A research infrastructure is also interested in traffic, but in this case it is the flOw of ideas (ie knowledge exchange), rather than passengers. In particular with a business model such as DARIAH has, which is supported by smaller national partner cash contributions and much larger in kind contributions, value will only be gained by partners if they feel that there is an effective and efficient flOw of information into the Hub and back out to them from other areas. This is a great challenge in knowledge enterprises in the humanities generally, where times to publication are traditionally long, and publication avenues for non-traditional forms of output are not always effective or valued. How can a research infrastructure effectively meet the challenges of directionality among its partner spokes, without infringing on institutional or individual IPR, but also without taking a merely reactive approach which does not necessarily keep the flOw of knowledge moving toward its final, transformative destination? In the airline/airport model, proper dimensioning represents a productive equilibrium between the overall incoming and outgoing capacity of people and baggage. Dimensioning ideas applied to a digital infrastructure works similarly, in analysing the amount of bandwidth needed to support users and the objects they access, both at the inward (preservation) and outward (access) service points. The efficiency of a digital infrastrastructure can therefore be measured according to how it achieves a balance in its services and approaches to services (client or server side), processing time and power, user expectation for when and how those services will be delivered, who will pay for these services, and how to develop a pricing model for them. Up- or downgauging occurs mainly in the context of freight, where a larger body of items is transitioned at the hub onto a larger or smaller aircraft, more suited to the total volume of cargo to be transported between the Hub and a given destination. Technical developments too sometimes come in packages that are too large for other projects to use in their entirety. How can a Hub facilitate the further uptake of parts of a larger project or set of workflOws elsewhere, both in terms of modularisation services but also the legal agreements needed for reuse of outputs from collaborative initiatives which may now have been disbanded? The area of Ancillary services is another opportunity that airline hubs are able to take particular advantage of due to their high traffic volume, and status as a place where people will spend more time in the airport itself (rather than passing through on the way from landside to airside and vice versa). If knowledge is passing through a research infrastructure, therefore, there may be opportunities to standardise it, enhance it or otherwise sell it a bottle of perfume before it moves on to the next user. What might these opportunities be, and how could DARIAH and its partners take advantage of them? Hub bypass is another issue which is worth considering in a digital humanities research infrastructure context. Sometimes, an airline finds it has enough traffic between two points that use of the hub is economically disincentivised. In these cases, normally a direct service between those points may be started, which increases effective transfer of passengers without the use of the Hub. In the digital humanities context too, there may also be times when specific projects or knowledge assets are so complementary that a strong bilateral may be a better model than a hub-and-spoke. But this should be the kind of opportunity that a digital infrastructure can foster and support, rather than be viewed as a (commercial) threat. This model will form the basis of a theory of the construction of the DARIAH infrastructure through its central hubs and spokes, including the DARIAH Coordination Office, national members at the governmental level, institutional participants, and individual EU funded research projects closely aligned to support DARIAH's mission, including the specific example of the Collaborative European Digital Archival Research Infrastructure, or CENDARI, project. [Key Words: Digital Infrastructure, DARIAH, Cyberinfrastrucure]'Integrating Independent Discovery and Analysis Tools for the HathiTrust Corpus: Enhancing Fair Use Digital Scholarship' J. Stephen Downie (Professor and Associate Dean, Graduate School of Library and Information Science, University of Illinois at Urbana-Champaign ) The HathiTrust Research Center (HTRC) is the research arm of the HathiTrust (HT). The HT corpus contains over 10 million volumes that comprise more than 3 billion pages drawn from some of the world's most important libraries. Founded in 2011, the HTRC is a unique collaboration that is co-located within two major institutions: University of Illinois and Indiana University. In this poster/demonstration, we introduce a new tool designed to enhance the ability of scholars to perform analyses across both the open and copyright-restricted data resources found in the HT corpus. Approximately 69%, or nearly 7 million volumes, of the HT corpus is under copyright restrictions. To allow for fair use analytic access to restricted works, the HTRC has developed a "non-consumptive research" model. This model provides secure fair use analytic access to large corpora of copyrighted materials that would be otherwise unavailable to scholars. In our model, analytic algorithms are run against a secured version of the corpus on behalf of scholars. Submitted algorithms are vetted prior to execution for security issues, and following execution only the analytic results are returned to the submitting researchers: scholars cannot reassemble the individual pages to reconstruct copies of the original restricted works. While the non-consumptive model is a significant step forward for allowing fair use analytic access to hitherto unavailable works, its algorithm-to-data constraints do inhibit the rapid and thorough prototyping of novel algorithms. To mitigate this shortcoming, we have combined the download and discovery functionality of the Greenstone digital library system [1] with the workflow functionality of the Meandre analytic environment [2] to operate in conjunction with the HT's bibliographic and data APIs. Using our new tool, scholars can create their own unique subsets from the HT corpus. For each work selected—both open and restricted—a bibliographic record is downloaded to their local environment. When a work is in the public domain (at the scholar's location), our tool can automatically download associated page images and text. We refer to this assembled content as the "prototyping workset." This approach helps scholars prototype new algorithms by affording them local access to as much full-text content as allowed by law, along with whatever other data to which they might have access rights unique themselves (i.e., novel annotations, locally-owned content, etc.). Once a scholar is satisfied with the behavior of their prototype, it can be submitted to HTRC to be run against the larger set of both open and restricted works.
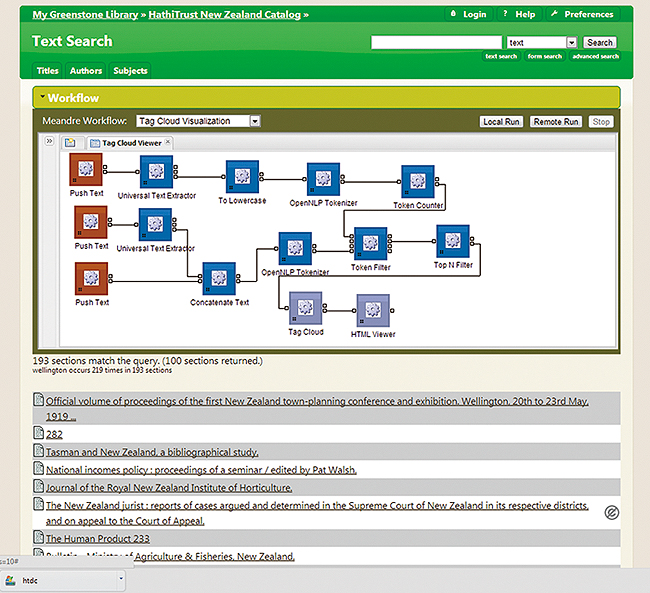
Figure 1 illustrates a worked example of a scholar studying language evolution in New Zealand. Bibliographic records for 7500 HT works associated with NZ have been located and downloaded using Greenstone's "download-from" plugin-architecture [3]. Figure 1 shows some of the 193 documents returned after a date limitation operation (1900–1949). Note entry number six (marked with the "public domain logo"): this document will be used for local prototype analyses. Above the returned documents, a drop-down list of available Meandre workflows is provided, from which a scholar has selected a time-based tag-cloud. After iteratively modifying this workflow, and then testing it on the prototyping workset, the finalized algorithm is then submitted to the HTRC system for vetting and subsequent execution. We believe that this "local prototype/remote execution" approach will enhance efficiency for both scholars and HTRC personnel alike as together they strive to realize the potential of fair use digital scholarship conducted against the invaluable resource that is the HT corpus. [Key Words: Content analysis, Text analytics, Non-consumptive research, Prototyping, Workset modeling]
References |
|
[SESSION 4] 'Framework of an Advisory Message Board for Women Victims of the East Japan Earthquake Disaster' Takako Hashimoto (Associate professor of Faculty of Commerce and Economics, Chiba University of Commerce)
After the East Japan Great Earthquake, women victims have been suffering from many problems and worries: they are caring of elders, raising children, finding jobs, needs for female-specific items and so on. Administrative authorities want to recognize these women sufferers' specific problems and give them appropriate and timely advisory information. However, in general, it is difficult to grasp their needs timely because their environments and conditions change from moment to moment, and take a lot of labor for interviews or questionnaire investigations. Therefore, if we could grasp victims' requirements from social media related to the East Japan Great Earthquake by a temporal data analysis, it would be quite useful. To properly an alyze and detect thechanging needs from their messages, we set the goal of our research is to construct anadvisory message board system on web that can classify their requirements. If we can detect the hidden topics of the requirement, we will be able to give victims appropriate advices. Even if we cannot help victims, at least, we could notice their requirements. Then we will make contact with a suitable non-profit organization, and the advisory message will be also sent to the client. [Key Words: East Japan Great Earthquake, women disaster victim, needs transition, data mining, advisory message board]
References 'The Daozang Jiyao Electronic Edition - Considerations for a Sustainable Scholarly Digital Resource" Christian Wittern (Professor at the Center for Informatics in East Asian Studies, Institute for Research in Humanities at Kyoto University) The [Daozang Jiyao Electronic Edition] is part of the result of an ongoing research project of a worldwide network of more than 60 scholars on Daoism during the Qing Dynasty with a special focus on the biggest collection compiled during that period, the Daozang jiyao 道臧輯要, 'Essentials of the Daozang'. It has been developed in close interaction with the researchers using the collection and strives to model the text in a way that is both faithful to the complicated textual tradition and useful for modern scholarly investigation. In this presentation, I will first give an overview of the methodological approaches to the digitization of the collection and how they have been put into practice. I will then introduce the textual model developed for this collection and discuss what potential it has beyond this research project. The next part of the presentation will introduce the website, which is currently in the beta-phase of development, to the audience as one part of the publication of the digital edition. One of the important questions every digitalization project has to answer is the question about the long-term perspective of the project after the initial period of funding has ended. As one possible vision for digital publication, I will introduce the idea of a repository (or even better, a network of repositories) for digital editions, that integrates well with other texts published in the same way and can thus form a source for personal digital repositories maintained by scholars themselves and containing exactly the texts that are needed. This will overcome serious problems with the current mainstream form of digital publication, namely a website as the sole venue of publication1. This topic has been discussed for some time and valid suggestions and a discussion of the requirements can be found in [1], [2], [3] and [4], which this presentation will take up and expand, namely by adding the requirement that the text will not only be made available to the scholarly community, but that it also be able to annotate it in a way that can be owned by the scholar adding the annotation and still be shared with interested colleagues. A proposal for a way to implement this will also be introduced and discussed. [Key Words: Text encoding, text representation, scholarly collaboration]
References
'Online Biographical Dictionaries as Virtual Research Environments' Paul Arthur (Professor of Digital Humanities at the University of Western Sydney) Online biographical dictionaries and related digital resources are supporting new research methods and enabling new findings in fields of biography, prosopography, genealogy and family history. Many long-running national biographical projects, such as the Australian Dictionary of Biography and the Oxford Dictionary of National Biography, have been migrated online in the past decade. Motivations for moving from print to digital have included enabling greater user access, more affordable publication formats, added flexibility in the way information is presented, the capability to correct and update efficiently, and allowing users to locate information more quickly with the promise of greater accuracy. The transition has also been driven by policies relating to engaging digital publics, including through crowdsourcing. Some online biographical projects are being conceived of as virtual research environments in their own right, allowing for sophisticated faceted searching, relationship mapping, analysis and visualisation of results in addition to standard information discovery. These transformations will be considered in the broader context of digital life writing as an emerging field in digital humanities. Particular reference will be made to the Australian Dictionary of Biography (ADB) online and associated projects, which support innovation in life writing in multiple media formats. Eighteen volumes of the dictionary and one supplementary volume have been published to date, consisting of a total of around 12,500 individual biographical articles. The ADB is the premier reference resource for the study of the lives of Australians who were significant in Australian history, and the largest ever collaborative project in the social sciences and humanities in Australia. |
|
[PLENARY 2] 'ODDly Pragmatic: Documenting encoding practices in Digital Humanities projects' James Cummings (Senior Digital Research Specialist for IT Services at University of Oxford) Use of the TEI Guidelines for Electronic Text Encoding and Interchange is often held up as the gold standard for Digital Humanities textual projects. These Guidelines describe a wide variety of methods for encoding digital text and in some cases there are multiple options for marking up the same kinds of thing. The TEI takes a generalistic approach to describing textual phenomena consistently across texts of different times, places, languages, genres, cultures, and physical manifestations, but it simultaneously recognises that there are distinct use cases or divergent theoretical traditions which sometimes necessitate fundamentally different underlying data models. Unlike most standards, however, the TEI Guidelines are not a fixed entity as they give projects the ability to customise their use of the TEI -- to constrain it by limiting the options available or extending it into areas the TEI has not yet dealt with. This combination of the generalistic nature and ability to customise the TEI Guidelines is both one of its greatest strengths as well as one of its greatest weaknesses: it makes it extremely flexible, but it can be a barrier to the seamless interchange of digital text from sources with different encoding practices. Every project using the TEI is dependent upon some form of customisation (even if it is the 'tei_all' customisation with everything in it that the TEI provides as an example). The TEI method of customisation is written in a TEI format called 'ODD', or 'One Document Does-it-all', because from this one source we can generate multiple outputs such as schemas, localised encoding documentation, and internationalised reference pages in different languages. A TEI ODD file is a method of documenting a project's variance from any particular release of the full TEI Guidelines. This same format underlies the TEI's own steps towards internationalisation of the TEI Guidelines into a variety of languages (including Japanese). The concept of customisation originates from a fundamental difference between the TEI and other standards -- it tries not to tell users that if they want to be good TEI citizens they must do something this one way and only that way, but while making recommendations it gives projects a framework by which they can do whatever it is that they need to do but document it in a (machine-processable) form that the TEI understands. Such documentation of variance of practice and encoding methods enables real, though necessarily mediated, interchange between complicated textual resources. Moreover, over time a collection of these meta-schema documentation files helps to record the changing assumptions and concerns of digital humanities projects. While introducing the concepts outlined above, this paper showcases projects from the University of Oxford as examples of the way in which this customisation framework can be used for real and pragmatic project benefits. [Key Words: Text Encoding Initiative, XML, Standards, Customization, Schemas] |
|
[SESSION 5] 'Designing the Chronological Reference Model to define temporal attributes' Yoshiaki Murao (The part-time lecturer of Nara University) The standard temporal attributes we can use in information systems are only"year", "month" and "day" in the Gregorian calendar, except shorter than a day. However, we usually categorize the historical issue that is already passed certain years into an "era", "age" or "period." Especially, in the history or archaeology, there are not so much information about the year of historical issues that they belong to and we can only know the "period" of the large majority of them. In current, the definition of era, age or period in the information system is not standardized practically. As it depends on the implementation of applications for each, it may cause the incompatibilities between databases stored and accumulated at many places, in the near future. In this paper, we introduce the "Chronological Reference model" (CR model) which expresses a type of temporal reference system commonly usable to define the era, age, period, generation or other types of temporal ranges and is able to apply them to temporal attributes of every objects in information systems. There are currently two major international standards for temporal attributes. One is ISO 8601 "Data elements and interchange formats – Information interchange – Representation of Dates and Times." It defines the basis of current rules of day or time in information system. The other is ISO 190108 "Geographic information – Temporal schema." It defines the schema to accept many types of calendars or eras. It also defines ordinal era to support the Jurassic period or the Cretaceous period, that are classified the order of periods but cannot be defined the start or end year of each period. We studied to apply the ordinal reference system of ISO 19108 to archaeological features or finds, and reached to design the CR model. The chronology is the term that defines and orders some periods. And its characteristics are similar to the ordinal reference system defined by ISO 19108. Hence we define the classes composed an original temporal reference system which inherit some classes as the ordinal reference system model and cover the chronological specifications. New classes defined in the CR model are ChronologicalSet, ChronologicalReferenceSystem, ChronologicalEra and some datatype classes. ChronologicalReferenceSystem class is the subtype of TM_OrdinalReferenceSystem class which is defined in ISO 19108, and ChronologicalEra class is from TM_OrdinalEra class. These classes have additional attributes or relationships to cover the chronological requirements. So the CR model is conformed to the international standard. We derived the CR model from the requirements of history or archaeology. But it is applicable to many other fields. The information which is aggregated and managed by the computer system will increase enormously in future. So the temporal category will become important to classify them, as same as the general or geographical category. With regard to the "period" which is used in general, we need the common specification which is unified controlled chronological definition and referenced each other. The CR model can be positioned there, and will play an important role when the variety of data is collected with chronological temporal attributes, referred by many researchers and analyzed them from chronological relationships. Actually it is already required now, because the information accumulation has been starting. The CR Model will contribute to the standardization of chronologies to set temporal attribute values appropriately for all information. [Key Words: Chronology, Temporal schema, Archaeology, History, Geographic Information System (GIS)] 'Ideal Type Modelling and Analysis - A Model Driven Approach in Cultural Sciences -' Yu Fujimoto (A Culture and Information Scientist. Lecturer at Department of Geography, Nara University) In the present day, nations are strongly connected and the importance of international cooperation is highly stressed in global society. However, such cooperation is still not easy despite various efforts to establish a healthy international society. To reach the next stage of a global society, understanding international conditions objectively will be essential. The problem is that each nation (or individual) has their own opinions, which have been derived from different materials, cultural and religious beliefs, and methodologies. Social conditions and these different viewpoints have caused conicts between nations, cultural regions, and/or individuals. Existing historical approaches of "documentation" have not thus far been able to overcome the problem. "Ideal Type Modelling and Analysis(ITMA) [1]", a methodology proposed by Fujimoto, and based on Max Weber's methodology of "Ideal Types [2]" and Object-oriented modelling (OOM), might offer a solution. The methodology offers a Model Driven Approach (MDA), enabling automated cultural studies. The researcher designs his or her own ideas or cognition to certain phenomena from the aspects of structures and various kinds of behaviours (or operations), and then, his or her aimed database schemas and programmatic source codes both for constructing the database and for analytical functions are generated automatically. Finally, the researcher receives his or her individual research database and the result of the analyses. The first information model designed is the "Ideal Types Model (ITM)", in which the models are stored in a model management repository when the database is constructed. Although the ITMA work-ow works for individual researchers, differences among researchers' ideas would be mathematically analysed by using stored ITM. Although the methodology is still developing and not get at a practical stage, it would provide a modernised-classical methodology for large volume of data in the present age. In this paper, the author will discuss one of the technical problems for generating programmatic source codes from ITM: how to generate such completed source codes. As with the original idea of Weber's ideal types, ITM should always be changing. Therefore, a method generating runnable programmes seamlessly from the models is required. The author is developing a test module generating the completed, not skeletal, source codes via the XMI (XML Metadata Interchange), which is commonly used in UML interchange. Although the UML/XMI do not specify to fact codes, in the current project, "note" or "annotation" fields for each class are utilised relating runnable source codes. In the annotation area, linkages to Python scripts are indicated, and the completed source codes are encoded when the corresponding XMI is parsed. The developing methodology of ITMA offers MDA in cultural sciences, and enables objective observation in social, historical and geopolitical phenomena. It provides reproducible and comparable interpretations for others. In this paper, the author discussed how the researchers' cognition is modelled, encoded and generated. The test module can generate runnable codes from a model. However, strict specifications for denoting linkages to the source codes are required, without changing the standardised grammars of UML and XMI. Additionally, version control methods will also be required if cultural science needs to trace the temporal transformation of each individual researcher's cognition. [Key Words: Ideal Types Modeling and Analysis (ITMA), Model Driven Research (MDR)]
References |
|
[PANEL 2] 'Exploring the Future of Publishing through Software Prototyping: Three Reports on a Workflow-Management User Experience Study' Geoff G. Roeder (Currently pursuing a second degree in Computer Science from that institution) Large-scale research projects in the digital humanities continue to grow in size and scope as more and more scholars take advantage of the opportunities for collaboration and study afforded by digital communication tools. Such projectsr equire a means to track and sort through large amounts of data, to assign tasks, and to define roles over sometimes large and geographically diverse teams of investigators. The larger the project, the greater is its need forcentralized workflow tracking and management—both for project managers and individual knowledge workers. Moreover, new digital environments have the potential to expand existing practices in the humanities to allow for new forms of engagement with and inter-disciplinary collaboration on both conventional print and born-digital, multimodal content. As McPherson (2013)remarks, these new opportunities challenge us to "… push beyond the idea that there is a single right interface to knowledge or one best way to publish" (p.10). The challenges and opportunities of this new scholarly context form the topic of this panel, explored through three studies of data collected during a recent user experience trial conducted by the Implementing New Knowledge Environments (INKE) group. As part of INKE's ongoing, multi-year research project into interface design and prototyping (see http://inke.ca/projects/about/), researchers at the University of British Columbia (Vancouver) and University of Alberta (Edmonton) conducted a two-phase study of two closely related project-management software prototypes. Both began as an experiment in the implementation of structured surfaces for visualizing project workflows (Radzikowska et al., 2011). This experimental prototype was customized for twopurposes: 1) to facilitate academic journal editing, and 2) to facilitate the Orlando Project's ongoing use of computing technology to study women's literary history (see http://www.artsrn.ualberta.ca/orlando/). These two medium-fidelity prototypes, Workflow Editorial Edition and Workflow Orlando, were then tested independently using the same instruments and experimental design on two separate participant pools (each having relevant professional experience). Participants engaged with the prototypes by following a task list, were encouraged to think aloud as they did so, and then filled out a questionnaire involving both Likert-scale and free response queries. Transcripts of these sessions along with the survey data collected provided information-rich grounds for an analysis of the benefits and challenges for both born-digital projects like Orlando and more conventional academic publishing. They also highlight what practices in interface design and testing can best facilitate users' feeling comfortable with and gaining the benefit of such workflows. This panel consists of three papers. The first paper, "Collaboration by Design: Institutional Innovation through Interface Aesthetics," discusses the potential for new modes of academic publishing and collaboration afforded by online workflow tools. The second, "Why is it doing that? Structural and ontological interface metaphors in Workflow," discusses observed patterns of behaviour among the participants in relation to theories of interface metaphor and design. The third paper, "Prospects and pitfalls of workflow management in born-digital projects," reports on the experience of expert users from the Orlando Project using the Workflow Orlando Edition. [Key Words: user testing; prototype; publishing; workflow; interface design] |
| [PLENARY 3] 'Transcending Borders through DH Networking in the Asia-Pacific' Paul Arthur (University of Western Sydney, Australia) With the rapid dissemination of collaboration between the humanities and the information technologies in the name of Digital Humanities (DH), many DH-focused research centers and academic associations have been established across the globe. The Asia-Pacific is one of the most fast growing areas in the movement. There are several centers that are not only working on the cultural and historical contents originated within their own regions, but also contributing to the world-wide DH community by providing e-Research platforms or introducing multimedia computing for the humanities. For example, the Digital Humanities Center for Japanese Arts and Cultures (DH-JAC) at Ritsumeikan University, which started in 2007, emphasizes on conducting synthetic research in DH concerning tangible and intangible cultural heritages. The Research Center for Digital Humanities at National Taiwan University (NTU) was launched in 2008, which has been conducting research projects to digitally preserve important, unique and delicate cultural artifacts and historical resources for promoting digital information exchange globally. Besides these centers, many research institutions and research groups in the area are actively taking responsibilities and initiatives for sharing digital methodsworld-wide, resources and research tools to sustain DH researchers and projects by collaborating with the Alliance of Digital Humanities Organizations (ADHO) and centerNet. In terms of academic associations, the Australasian Association for Digital Humanities (aaDH) was formed in 2011 to serve a growing digital research community in Australia, New Zealand and more widely in the regions of Australasia and the Pacific. The Japanese Association for Digital Humanities (JADH) was also launched in 2011, which has been aiming to align DH-related domestic associations and promote international collaborative works. The Research Center for Digital Humanities at NTU has been organizing international conferences on Digital Archives and Digital Humanities since 2009 to encourage collaboration between the information technologies and domain experts in the humanities and social studies for accumulating massive digitized collection and promoting interdisciplinary connections. This panel session invites three leading scholars who are actively involved in fostering and developing DH community in the Asia-Pacific area. They will share the information about the trend in DH-related scholarly activities in each county/region. They will also discuss how collaborative activities and scholarly networking in the area will be able to transcend the particularity of each region for contributing to the knowledge creation in the global DH community. |

